“程序=数据结构+算法”
——Pascal语言之父-Nicklaus Wirth
一、绪论
1.1 研究内容
具体问题抽象为数学模型->分析问题、提取操作对象、找出操作对象间的关系、用数学语言描述。其中,操作对象和对象间的关系也就是数据结构。如何根据关系状态来解决问题用的方法就是算法。📐📏
1.2 基本概念于术语
(1)数据
数据是能输入计算机且能被计算机处理的各种符号的集合。包括数值型数据:int、float等;非数值型数据:文字、图像、声音等。
(2)数据元素与数据项
数据元素是数据的基本单位,在计算机程序中通常作为一个整体进行考虑和处理;数据项是数据元素不可分割的最小单位。比如,学生李华的姓名、学号、年龄等是一个数据元素,其中的姓名就是一个数据项。
(3)数据对象
数据对象是性质相同的****数据元素的集合,是数据集合的子集。比如整数集合,字母集合。
我画了如下一张图来表示他们之间的关系👇📣:
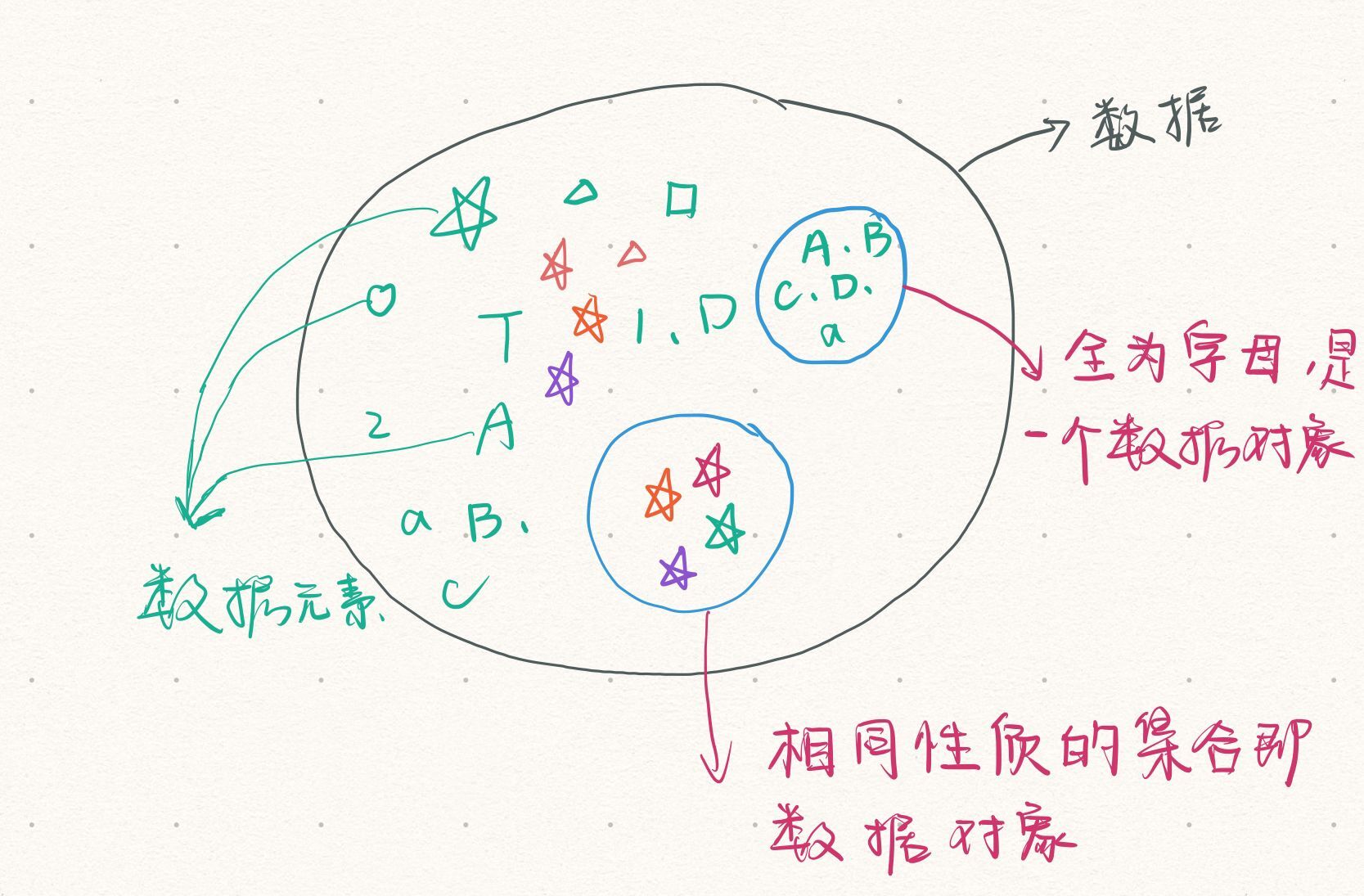
(4)数据结构
数据结构是带结构的数据元素的集合;结构是指数据元素之间的关系。
数据结构的分类:
- 逻辑结构:数据元素之间的逻辑关系
- 物理(存储)结构:数据元素及其关系在计算机内存中的表示(又称映像)
- 运算和实现:对数据元素的操作
逻辑结构和存储结构的关系:
- 存储结构是逻辑关系的映像与元素本身之间的映像
- 逻辑结构是数据结构的抽象,存储结构是数据结构的实现
- 两者建立了数据元素之间的结构关系
逻辑结构的种类: - 线性结构:最多只有一个直接前驱和直接后继
- 非线性结构:可能有多个直接前驱和直接后继
存储结构的分类: - 顺序存储:用一组连续的存储单元依次存储数据元素,数据元素之间的逻辑关系由元素的存储位置决定的。C语言中用数组表示
- 链式存储:用一组任意的存储单元存储数据元素,数据元素之间的逻辑关系用指针来表示。
- 索引存储:在存储信息的同时,还建立了附加的索引表。
- 散列存储:根据结点的关键字直接计算出该结点的存储地址。
(5)数据类型
- 数据类型
包括int、float等基本数据类型,数字、结构、共用体等构造数据类型,指针。
数据类型是一组性质相同的值的集合和定义于这个值集合上的一组操作的总称。 - 抽象数据类型(ADT)
形式定义:(D、S、P)三元组表示,
D:数据对象; S:对象的关系集合; P:对D的基本操作集合
定义格式:
ADT 抽象数据类型名{
数据对象:定义
数据关系:定义
基本操作:定义
} ADT 抽象数据类型名
其中基本操作的定义内容为:
参数表:赋值参数,为操作提供输入值;引用参数:用连字符&表示,返回操作结果、
初始条件和操作结果。
概念小结:
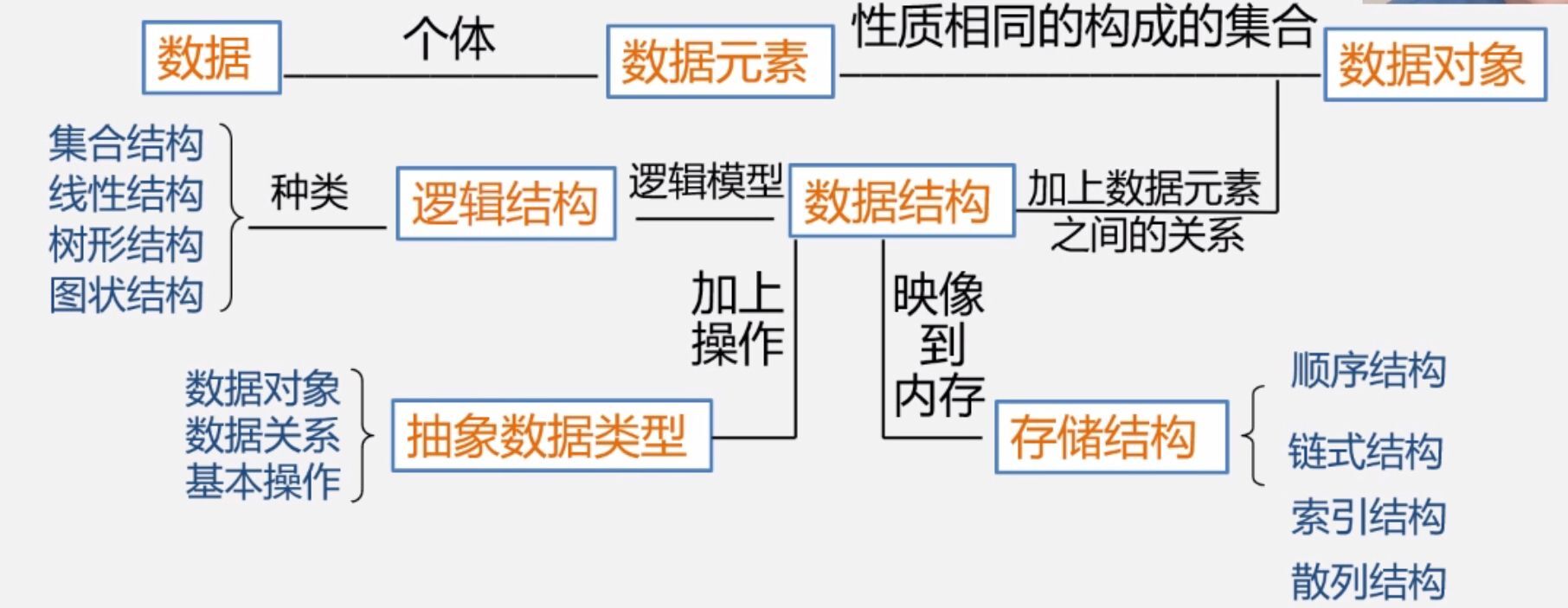
1.3 算法与算法分析
1.3.1 算法特性:
- 有穷性
- 确定性
- 可行性
- 输入
- 输出
1.3.2 设计要求
- 正确性
- 可读性
- 健壮性
- 高效性
1.3.3 算法效率
算法的复杂度分析是事前估计,考虑其最坏情况,用大写O(f(n))表示。
(1)时间复杂度
算法运行时间= (语句频度)每条语句的执行次数执行时间之和
—>单次执行时间由机器决定,所以算法运行时间只讨论语句频度
如何计算时间复杂度:
计算规则:忽略常数、忽略系数、只取最高次项。
计算流程:算法中基本语句重复执行的次数是问题规模n的某个函数f(n),算法的时间量度记作:T(n)=O(f(n)),O(f(n))称为算法的渐进时间复杂度(O是数量级的符号),简称为时间复杂度。
首先,找到基本语句(即执行次数最多的语句),
还有关于问题规模n的函数f(n):
- 排序:n为记录数
- 矩阵:n为矩阵的阶数
- 多项式:n为项数
- 集合:n为元素个数
- 树:n为树的结点个数
- 图:n为图的顶点数或边数
最后用O表示
计算方法:
定理一:找最高次项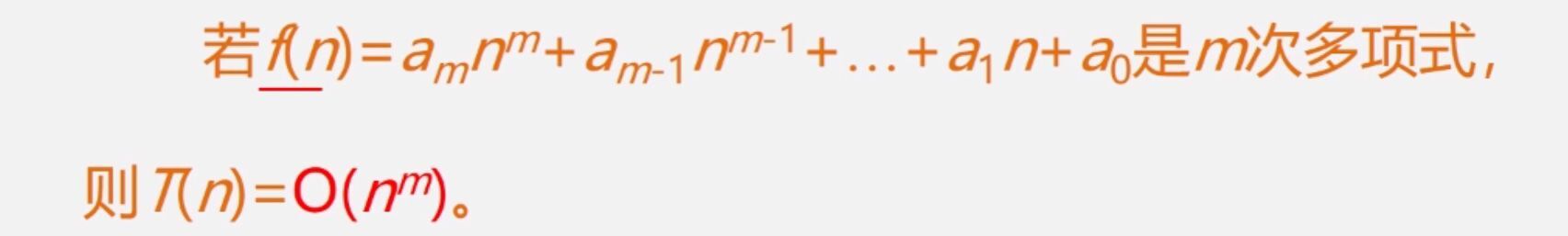
例子: - for循环:嵌套几个for循环,时间复杂度就是n的多少次方
- 关于log2n的问题
- ...
常见时间复杂度: - 执行常数次操作:O(1)
- 二分查找:O(logN)
- 线性查找:O(N)
- 归并排序、快速排序:O(NlogN)
- 选择排序、插入排序:O(N^2)
- 搜索算法:O(2^N)
二、线性表
逻辑结构分为线性结构和非线性结构,其中线性结构有线性表、栈、队列、字符串、数组、广义表等。
线性表有两种基本存储结构:顺序存储和链式存储。
1.1 线性表的定义及特点
(1)定义
线性表是具有相同特性的数据元素的有限序列,记作(a1,a2,a3, a4, a5, a6......an),其中a1为线性起点,an为线性终点,a3的直接前驱是a2,直接后继是a4;数据元素的个数n叫表长,n=0是叫空表。
(2)特点
- 开始节点:有且只有一个,没有直接前驱,有且只有一个直接后继
- 终端节点:有且只有一个,没有直接后继,有且只有一个直接前驱
- 中间节点:有且只有一个直接前驱,有且只有一个直接后继
(3)案例
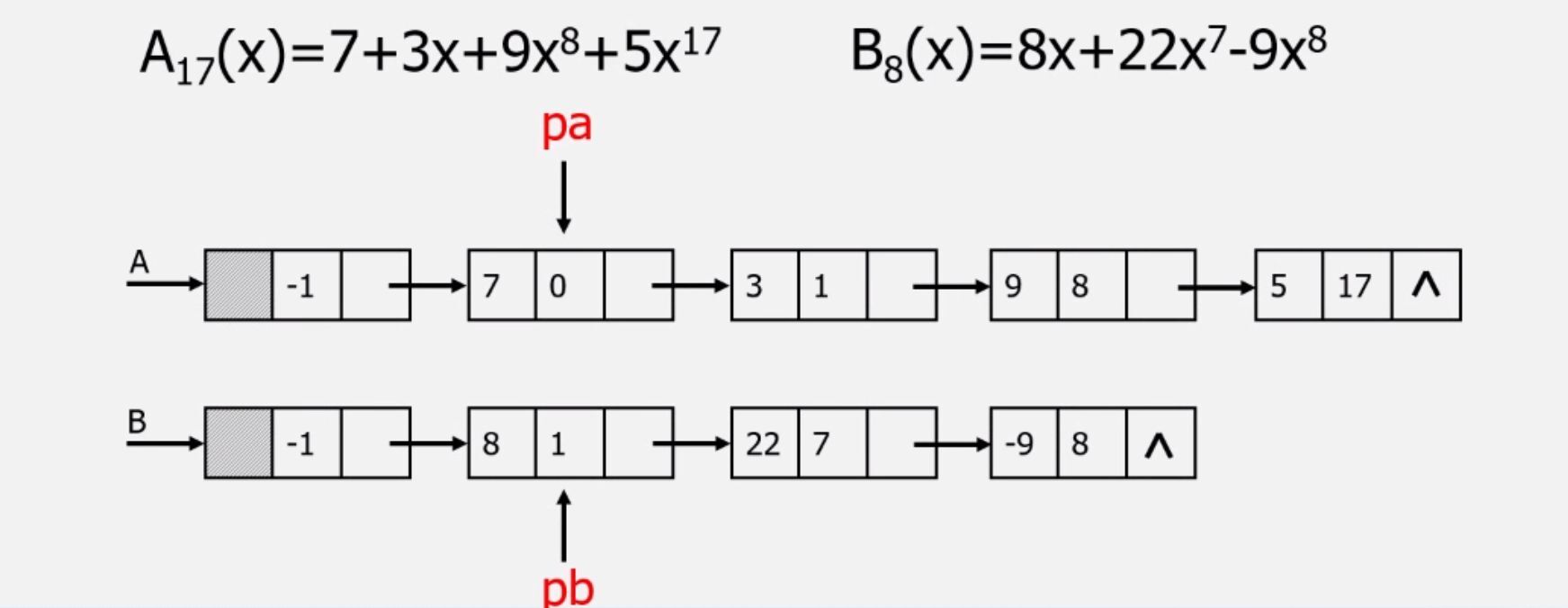
- 稀疏多项式:没有包含所有x的幂的多项式
如A=7+3x+9x8+5x17
B=8x+22x7-9x8
用线性表表示:p=(系数,指数)
A=((7,0),(3,1),(9,8),(5,17))
B=((8,1),(22,7),(-9,8) - 线性表运算:
先创建一个新数组C,分别遍历比较A、B里面的项:
- 指数相同,系数相加,其和不为零,则加到C中
- 指数不同,将指数较小的复制到C中
按照此方法:C=((7,0),(11,1),(22,7),(5,17))
那么,新数组的大小应该定义成多大呢?显然并不好操作。我们可以用更合适的链式存储结构来存储A+B:
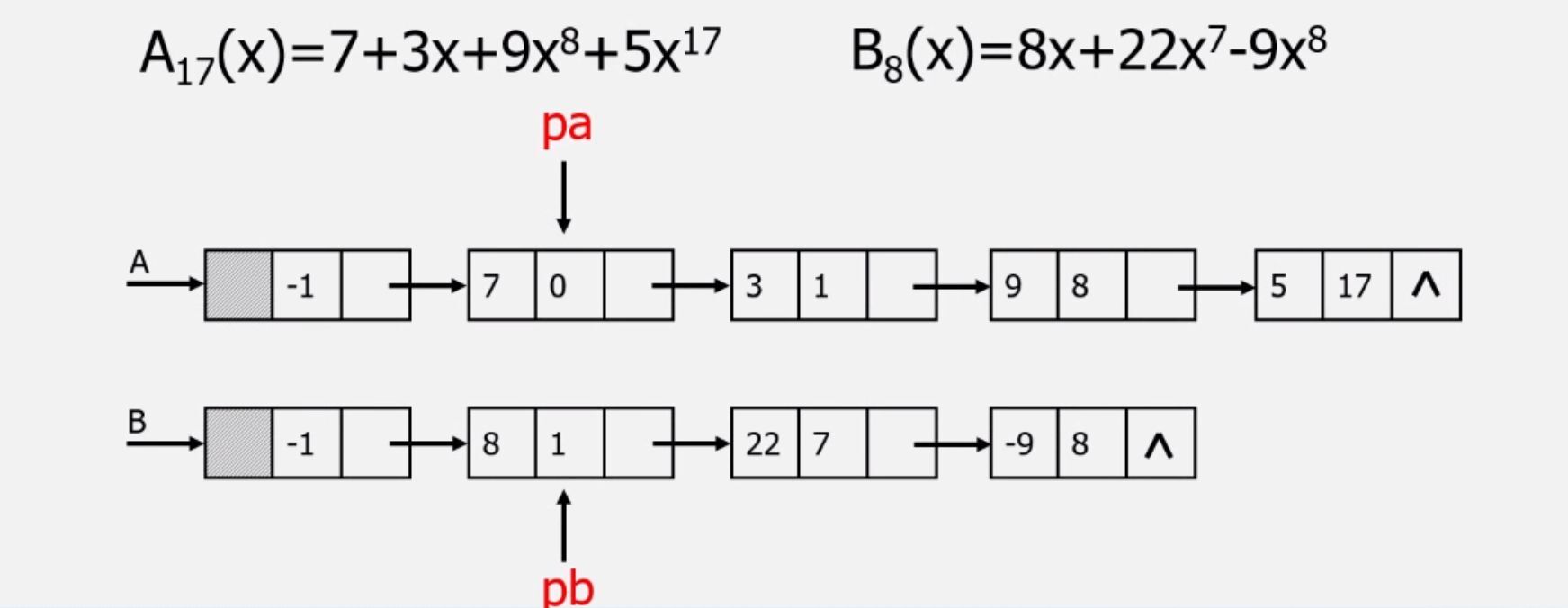
还是分别遍历A,B:
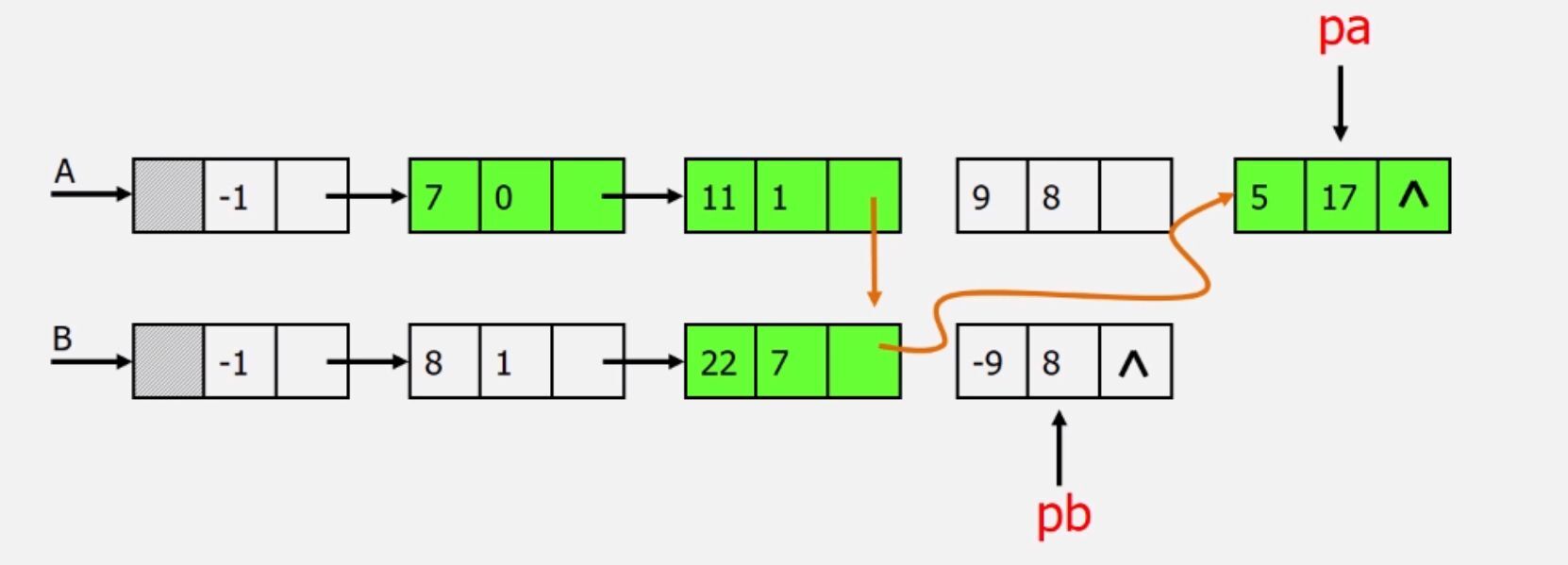
1.2 线性表的类型定义

(1)基本操作
InitList(&L):初始化,构造一个空的线性表L
DesyroyList(&L):销毁已存在的线性表L
ClearList:清空重置已存在的线性表L
ListEmpty(L):判断线性表是否为空,返回True或False
ListLength(L):计算线性表的元素个数
GetElem(L,i,&e):若1<=i<=ListLength(L),用e返回第i个元素
LocateElem(L,e,compare()):compare()为数据元素判定函数,返回第一个与e满足compare()的数据元素
PriorElem(L,cur_e,&pre_e):c当ur_e不是第一个元素时,用pre_e返回cur_e的前驱。
NextElem(L,cur_e,&next_e):c当ur_e不是最后一个元素时,用next_e返回cur_e的后继。
GetElem(&L,i,e):若1<=i<=ListLength(L)+1(最后一个元素的后面),在第i个位置插入新的元素e,L的长度加1。
ListDelete(&L,i,&e):若1<=i<=ListLength(L),删除第i个元素,并用e返回其值,L长度减1.
ListTraverse(&L,visited()):遍历
1.3 线性表的顺序表示和实现
顺序表示又叫顺序存储(顺序映像);
特点:地址连续、依次存放、随机存取、类型相同。
优点:存储密度大,随机存取任意元素
缺点:插入删除操作时,需要移动大量元素;浪费存储空间;静态存储,元素个数不可自有扩充。
定义:把逻辑上相邻的数据元素存储在物理上也相邻的存储单元中的存储结构,它占用了一片连续的储存空间。
故,可以计算出某个元素的位置。
公式:LOC(a_n)=LOC(a_m)+(n-m)*i
其中,已知第m个元素的位置和每个元素占用i个存储单元,求第n个元素的位置(n>m)。
若已知第一个元素,就变成了:LOC(a_n)=LOC(a1)+(n-1)*i
根据顺序表特点可用一维数组来表示:
线性表长可变-->用一变量表示顺序表的长度属性
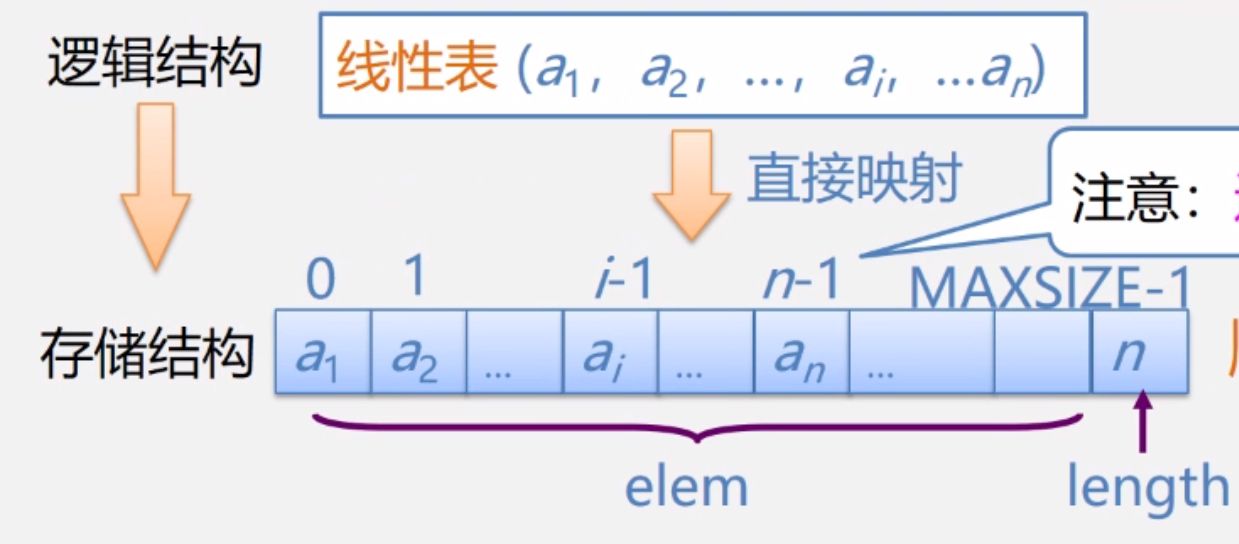
注意:线性表顺序存储时的逻辑结构下标是从1开始,存储结构是从0开始的(因为存储在数组),因此,逻辑位序比物理位序多1。
1.4 顺序表基本操作的实现
(1)初始化
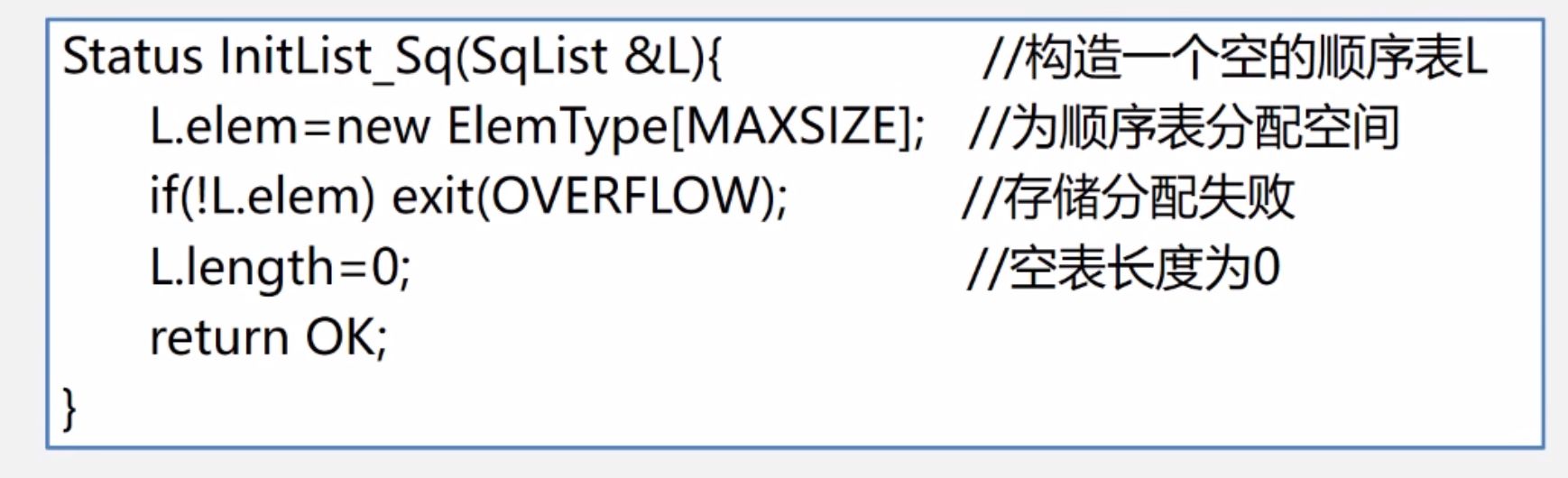
(2) 销毁与清空线性表
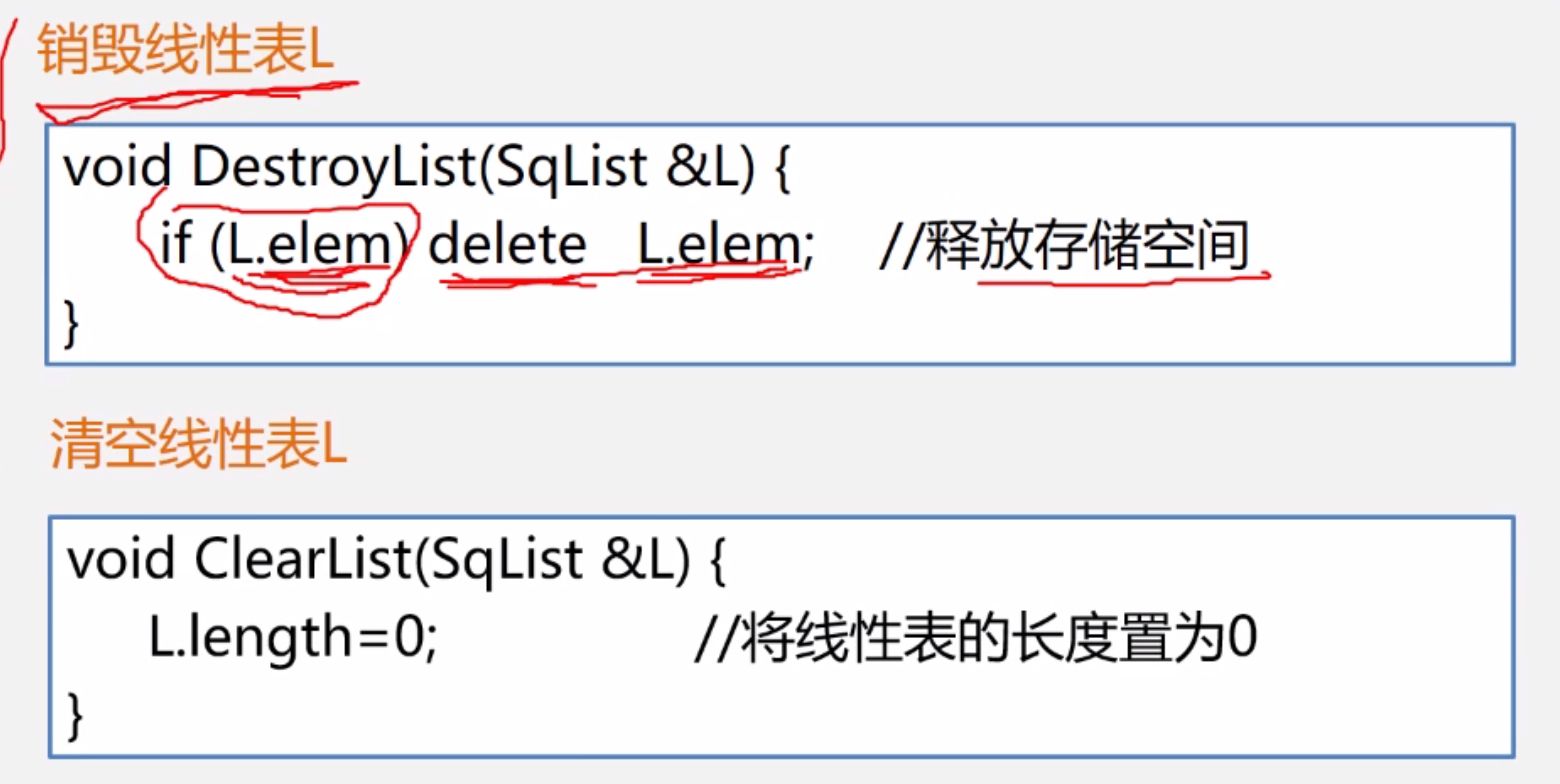
(3)线性表长度
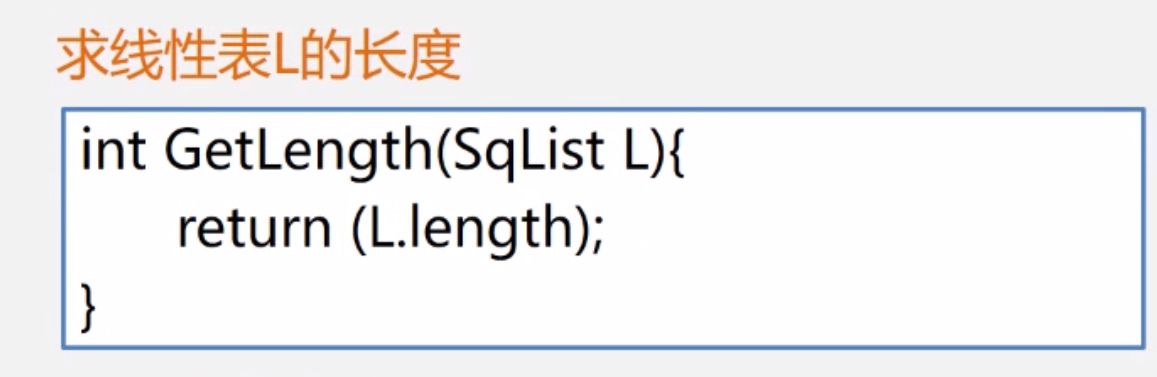
(4)判断是否为空
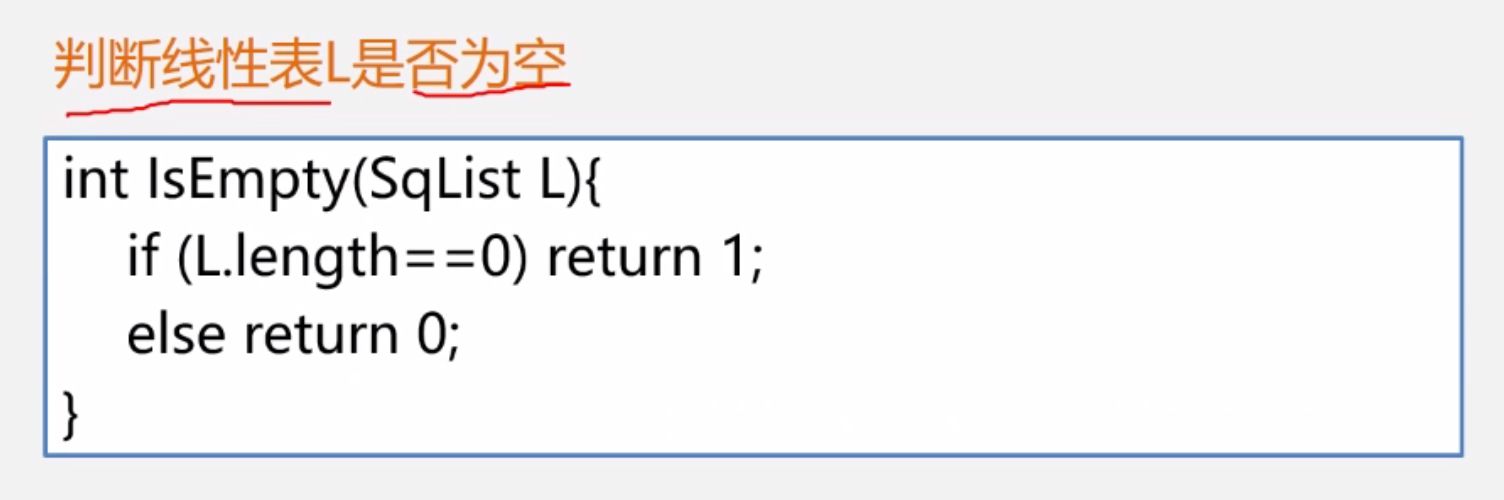
(5)顺序表取位置为i的值
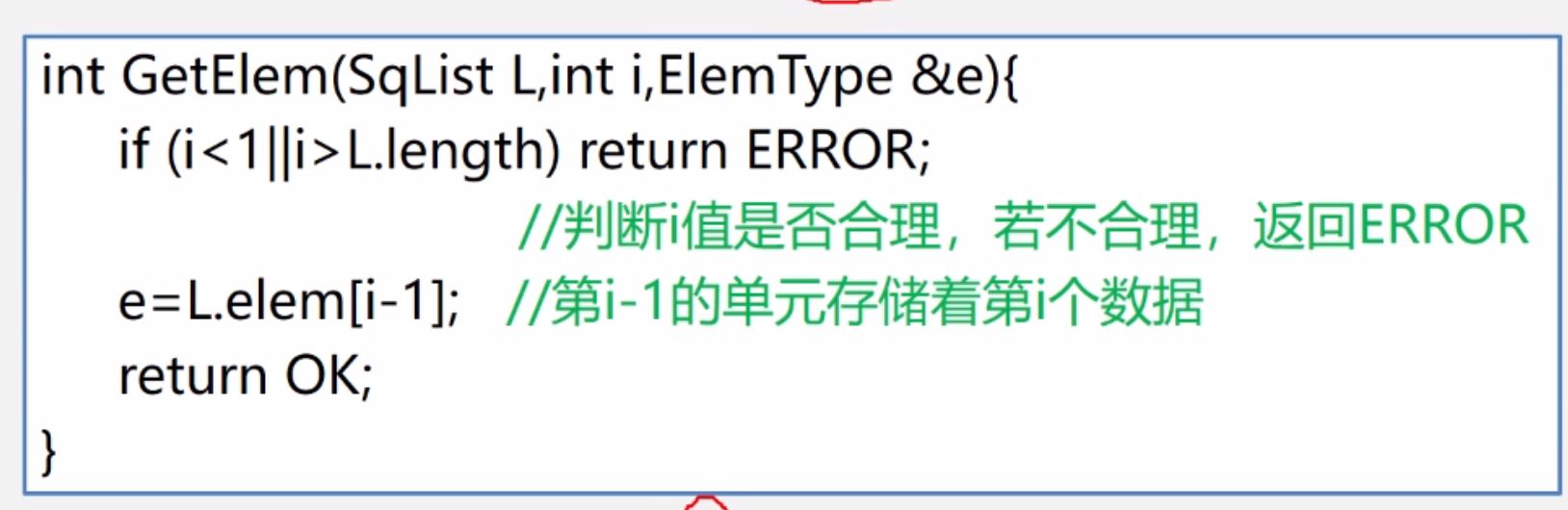
(6)按值查找
在线性表中查找与指定值e相同的是数据元素的位置,从表的一端与表中数据逐个比较,找到返回位置序号,未找到返回0。

平均查找长度(ASL):
为确定记录在表中的位置,需要与给定值进行比较的关键字的个数的期望值叫做查找算法的平均查找长度。
简单来说,就是所有情况下的查找次数之和除以元素个数就是ASL。
ASL=∑PiCi (i=1,2,3,…,n),可以简单以数学上的期望来这么理解。其中:Pi 为查找表中第i个数据元素的概率,Ci为找到第i个数据元素时已经比较过的次数。
(7)插入算法
算法思想:
- 判断插入位置i是否合法(1~n+1)
- 判断存储空间是否已满(i<l.length)
- 将第n个位置至第i位的元素依次往后移动一个位置,空出第i个位置。
- 将要插入的新元素e放入第i个位置
- 表厂+1
插入情况:
①插入位置在最后
②插入位置在中间
③插入位置在最前面
算法实现:

算法分析:ASL=(n+...+1+0)/n+1=n/2
时间复杂度位O(n)
(8) 删除操作
删除情况:
- 删除位置在最后
- 删除位置在中间
- 删除位置在最前
算法思想:
①判断删除位置是否合法(1~n)
②将欲删除的元素保留在e中(可选)
③将第i个元素至第n位的元素依次向前移动一个位置
④表长-1,删除成功返回ok
算法实现:
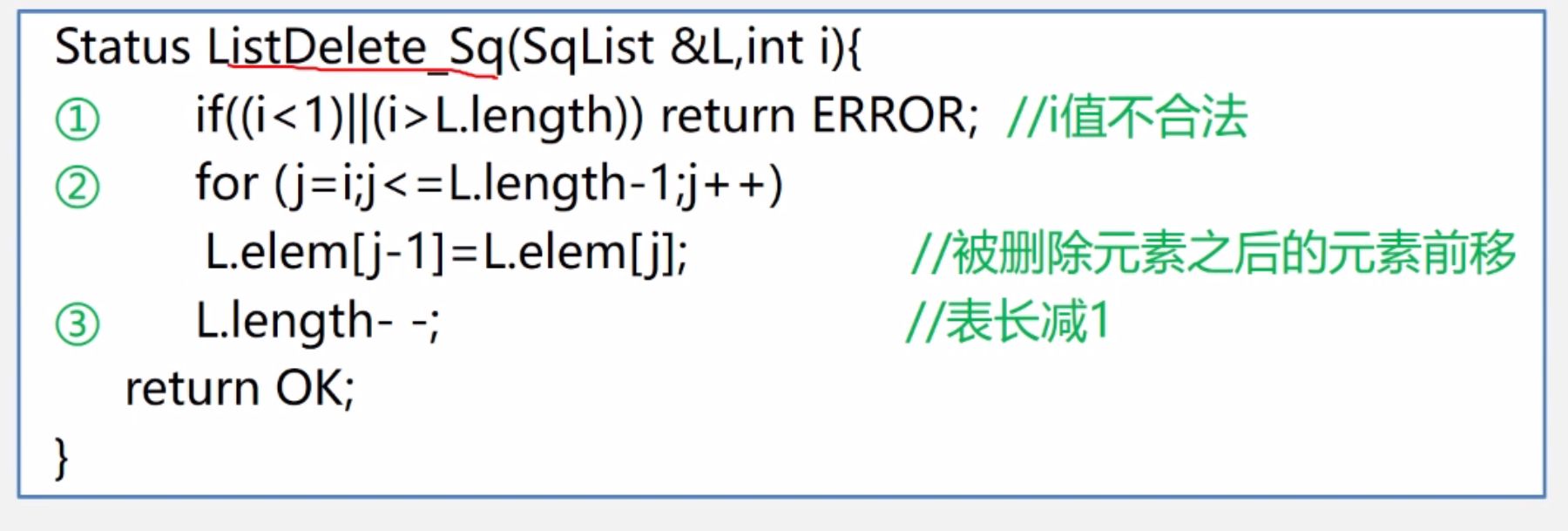
算法分析:
ASL:
(n-1+n-2+n-3+...+0)/n=(n-1)/2
时间复杂度:
O(n)
1.5 线性表的链式表示和实现
1.5.1 表示
(1)概念
①结点
数据元素的存储映象。由数据域和指针域两部分组成。
| 数据域 | 指针域 |
|---|
数据域是存储元素数值数据;指针域是存储直接后继结点的存储位置(地址)
②链表
n个结点由指针链组成一个链表。
Head ->| 数据a | 指针p1 | ->| 数据b | 指针p2 | ->| 数据c | NULL |
③头指针
链表中第一个结点(即第一个数据元素的存储映像)的存储位置。当存在头结点时头指针指向头结点的数据域,当不存在头结点时,头指针指向首结点。
头指针具有标识作用,故常用头指针冠以链表的名字。
无论链表是否为空,头指针均不为空。头指针是链表的必要元素。
(2) 链表分类
①单链表(或线性链表)
结点只有一个指针域的链表
单链表是由表头唯一确定的,故单链表可以用头指针的名字来命名,若头指针名是L,则叫做链表L。
②双链表
每个结点有两个指针域的链表
③循环链表
首尾相接的链表
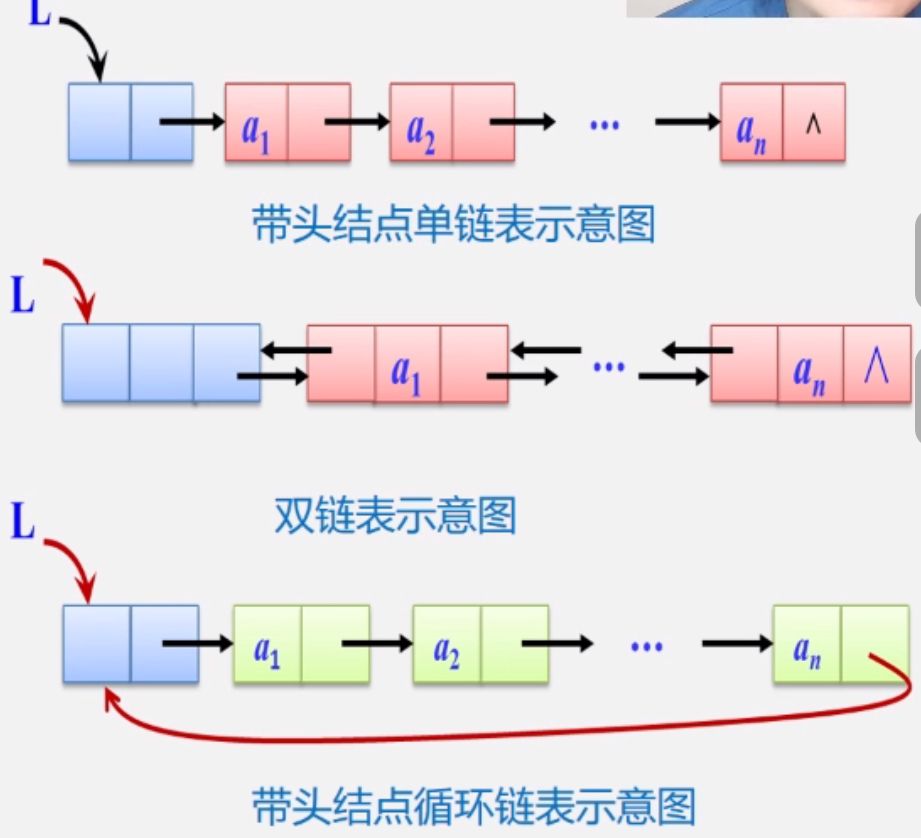
补充:
- 怎么表示空链表?
无头结点时,头指针为空表示空表
有头结点时,当头结点的指针域为空表示空表 - 设置头结点有什么好处?
- 便于首元节点的处理
首元结点的地址保存在头结点的指针域中,所以在链表的第一个位置上的操作和其他位置一致,无需进行特殊处理。 - 便于空表和非空表的统一处理
无论链表是否为空,头指针都是指向头结点得非空指针,因此空表和非空表的处理也就统一了。
- 头节点的数据域存放着什么?
头结点的数据域可以为空,也可以存放线性表长度、监哨所等附加信息,但此结点不能计入链表长度值。
(3)链表特点
- 结点在存储器中的位置是任意的,即逻辑上相邻的数据元素在物理上不一定相邻。
- 只能通过头指针访问链表,并通过每个结点的指针域依次向后顺序扫描其余结点。
顺序表 -> 随机存取 eg:访问第i个元素,a[i-1];
链表 -> 顺序存取 eg:访问第i个元素,要从1,2,3,...i依次访问到i。
(4)单链表
定义:
链表有单链表、双链表以及循环链表。其中,重点介绍单链表。
单链表是由表头唯一确定的,故单链表可以用头指针的名字来命名,若头指针名是L,则叫做链表L。
存储结构:
| 数据域 | 指针域 |
|---|
| data | next |
|---|
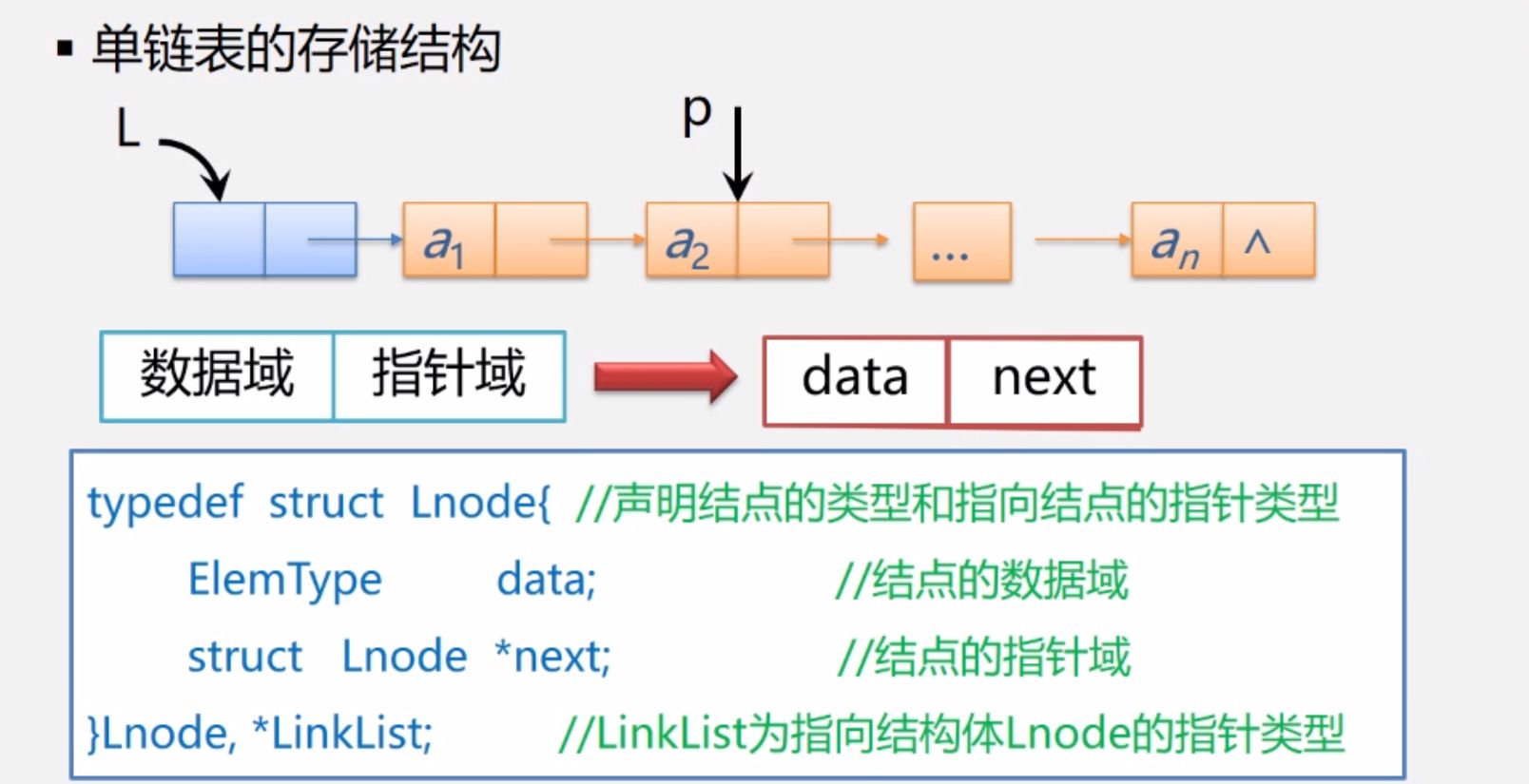
定义链表L:LinkList L;
定义结点指针p: LNode *P;
栗子
typedef struct student{
char num[8];
char name[8];
int score;//前三都是数据域
struct student *next;//指针域,next指针指向下一个节点,指针类型是包含四个成员的struct student
}Lnode,*LinList;
LinkList L;
或者
typedef struct{
char num[8];
char num[8];
int score;
}ElemType;
typedef struct Lnode {
ElemType data;//数据域
struct Lnode *next;//指针域
1.5.2 基本操作的实现
(1)单链表的初始化(带头结点的单链表)
| ^ |
|---|
步骤:
- 生成一个新节点作为头结点,用头指针L指向头节点
- 将头结点的指针域置空
描述:
Status InitList_L(LinkList &L){
L= new LNode;或 L=(LinkList)molloc(sizeof(LNode));//创建一个头结点
L->next=NULL;//将头结点的指针域置空
return 0;
}
补充:
- 判断链表是否为空
空表:链表中无元素,但头指针和头结点还在
思路:判断头结点的指针域是否为空
算法描述:
int ListEmpty(LinkList){
if(L->next)//若链表为空,返回0;不为空返回1
return 0;
else
return 1;
}
- 单链表的销毁
链表销毁后不存在(头结点也会消失)
思路:从头指点开始,依次释放所有结点;
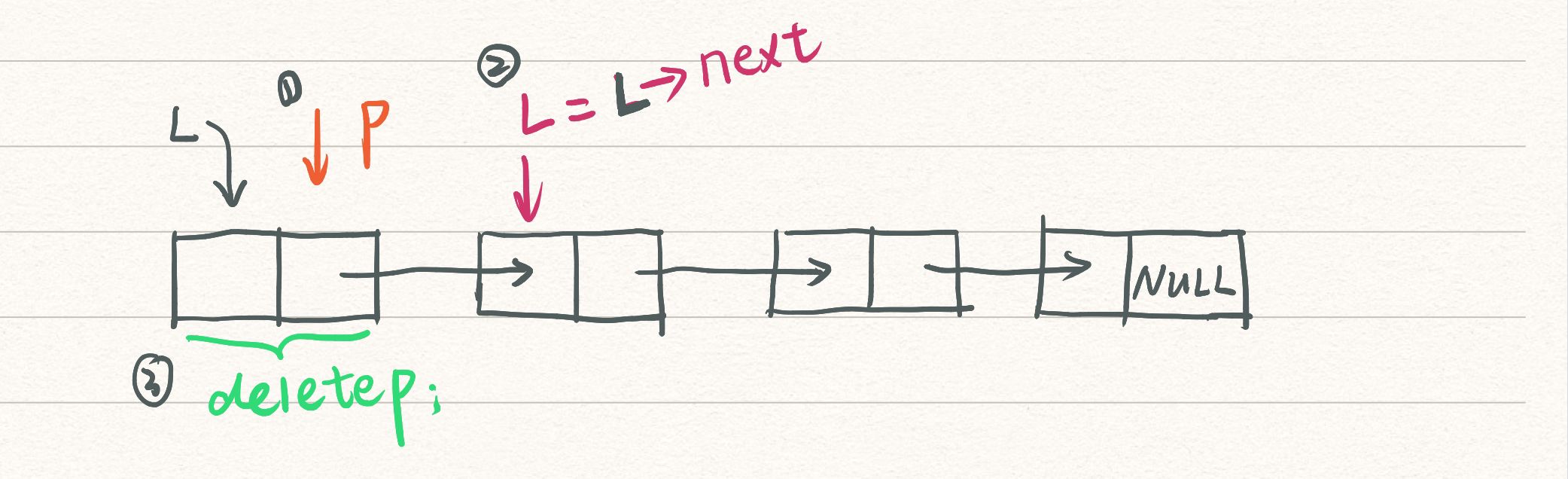
算法描述:
Status DestoryList_L(LinkList &L){
LinkList p;//Lnode *p;
while(L){
p=L;//p指针指向头结点
L=L->next;
delete p;
}
}
- 清空单链表
链表仍存在,但链表无元素,成为空链表。(头结点仍存在,,其他节点删除)
Status DestoryList_L(LinkList &L){
Lnode *p;*q;//或LinkList p,q;
p=L->next;//p存放要删除的结点
while(L){
q=p->next;//q存放下一个节点
delete p;
p=q;
}
L->next=NULL;
return OK;
}
- 单链表的表长
从首元结点开始,每访问一个节点,表长i就+1(头结点不算入表长)
Status DestoryList_L(LinkList L){
Lnode *p;
int i=0;
p=L->next;//p指向首元结点
while(p){
i++;//p不为空,表长就加1
p=p->next;
}
return i;
}
(2) 取值-取单链表中第i个元素的内容
从第一个结点出发,顺着链域next逐个结点往下搜索,直至搜索到第i个节点为止。因此,链表不是随机存取结构。
算法描述:
Status GetElem L(LinkList L,inti,Elemtype &e){
p=L->next;i=1;
while(p&&j<i){
p=0->next;
++j;
}
if(!p||j>i) return ERROR;
e=p->data;
return OK;
}//GetElem_L